Tutorial: How to Pull Data From a Website to Google Sheets
Pull content from a website to a spreadsheet without scraping (⏲️ 15 Minutes)
Don't write a web scraper. Nobody likes doing it, and it's a pain to maintain. Just look at this rule that only pulls the title of the first post on our blog.
=IMPORTXML("https://blog.diffbot.com","//*[@id="post-24545"]/div/div/header/h2/a")
It's a mess, even for experienced programmers.
Instead of writing complicated scraping rules, we'll use fact finding AI to extract it for us.
In this tutorial, we'll install the Diffbot for Sheets add-on, then walk through a few different ways to pull data from websites.
Let's get started.
Pre-Requisites
- A Diffbot Token (register for a free plan here and copy your token once logged in)
- A Google account with access to Google Sheets
Step 1: Install the Google Sheets Add-on
Head to the Diffbot for Sheets Add-on page on Google Workspace Marketplace. Click install and follow the instructions to complete installation.
Step 2: Authenticate with Diffbot
Open a new or existing spreadsheet on Google Sheets. Head to Extensions > Diffbot for Sheets > Login to Diffbot.
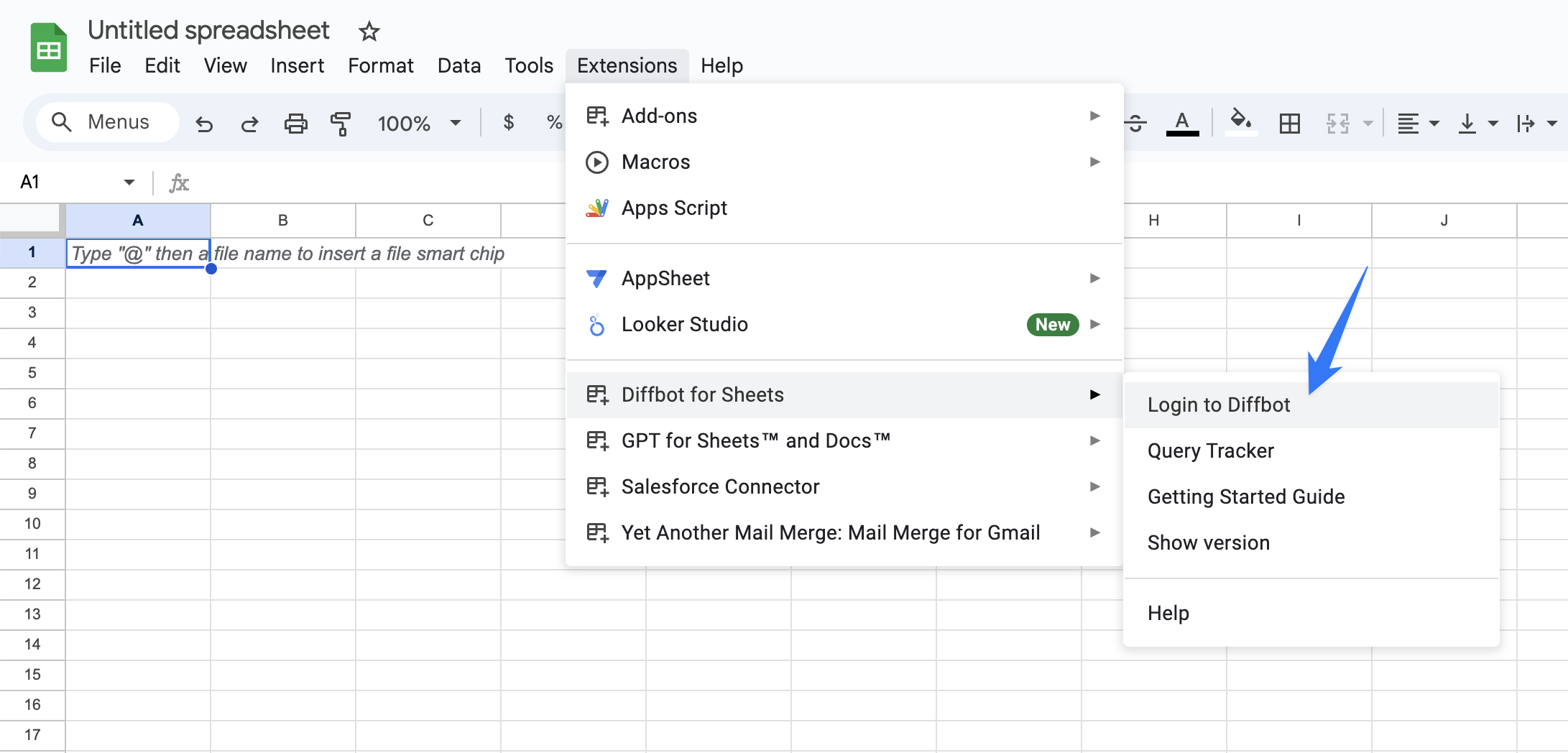
Enter your Diffbot token and click OK. You're all setup!
Step 3: Pull Data from a Website
While the Diffbot for Sheets add-on includes a few other functions, this tutorial will focus on just one — EXTRACT_URL(). Activate it by choosing any cell and type the following
=EXTRACT_URL
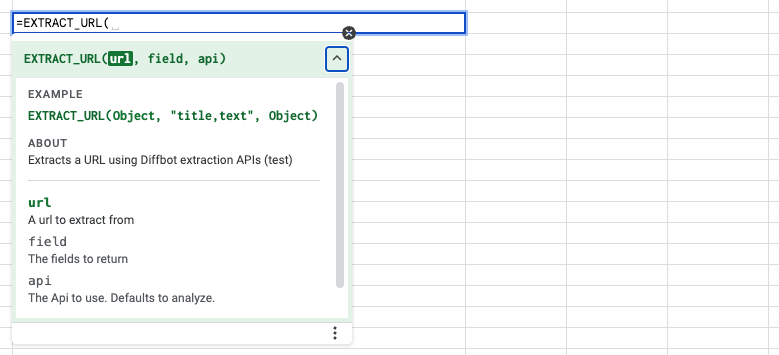
Usage of this function is fairly straight forward. Let's run through each argument.
| Argument | Description | Example |
|---|---|---|
url | The URL of the website to extract | https://blog.diffbot.com |
field | Comma delimited list of data fields to extract (see Ontology) | "items.title, items.link" |
api | Type of page to extract. See below for the full list. | "list" |
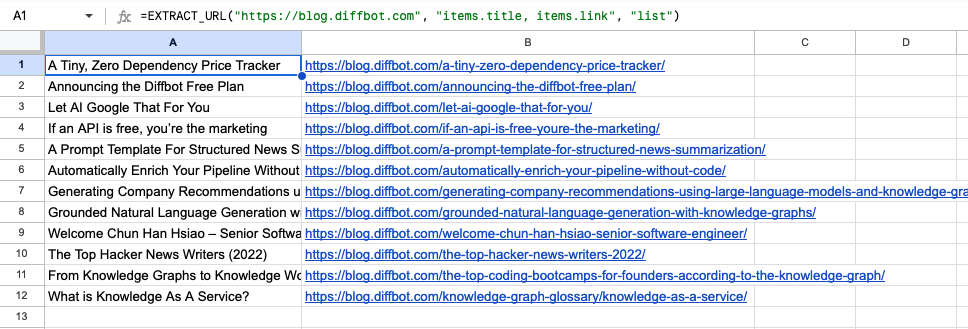
We'll start by extracting a list of posts from Diffbot's blog (https://blog.diffbot.com). To do this, follow the example values for EXTRACT_URL above like so.
=EXTRACT_URL("https://blog.diffbot.com", "items.title, items.link", "list")
listis kinda specialUnlike the other API types,
listtells Diffbot Extract there is a list somewhere on the page that you want to extract. On finding this list, it will then extract a list ofitems. Each item is returned as multiple rows in your sheet. See Pull List Data for more details.For all other API types, only a single row is returned (one field for each column).
We should now have several rows of blog post titles and links. For each blog post, let's now extract an author as well as the full text. A blog post is a type of article, so we'll use the article API.
=EXTRACT_URL(B2,"author,text","article")
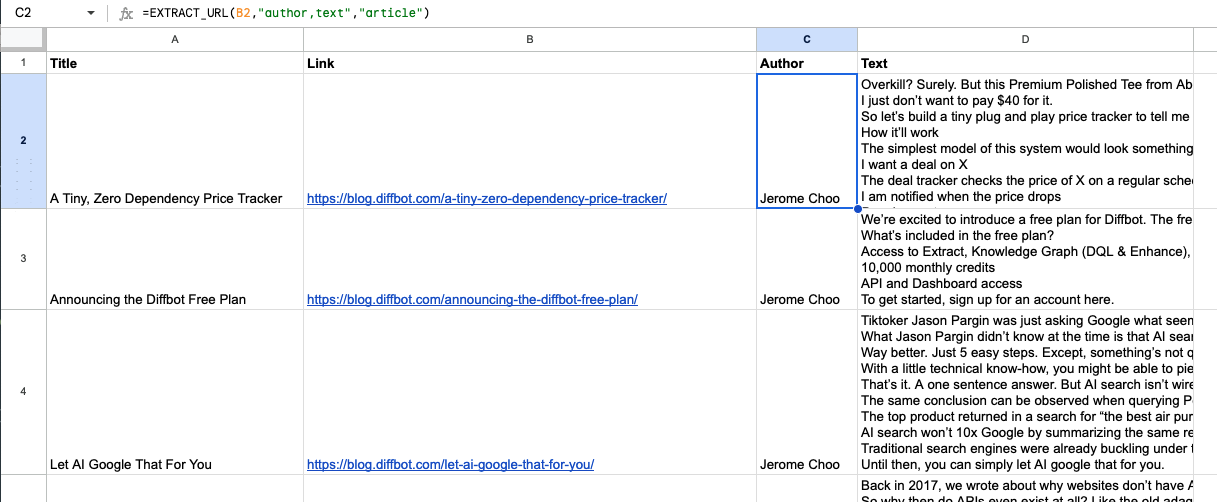
That's it! This same workflow can be used to extract press releases and many other lists of articles.
Next, we'll cover some other types of data you can pull and include a reference of data fields available to each.
API Types
The api type argument tells Diffbot Extract what kind of data you'd like to extract from the page. In addition, to article and list, which we've covered above, we'll share some of the other types of data you can pull.
Pull Article Data
The article API type should be used for blog posts, press releases, essays, research papers, or any other piece of long form writing. A complete list of data fields extracted by the article api is available here.
Here's an example of extracting the title, author, and text from an article —
=EXTRACT_URL("https://blog.diffbot.com/let-ai-google-that-for-you/","title,author,text","article")
For more on article api, check out the article API reference.
Pull List Data
The list API type tells Diffbot Extract that there is a list somewhere on this page that we want to extract.
A list is any set of repeated sections on page, like a table of data, a list of conference speakers, or an agenda. list API is intended to be broad and flexible.
If Extract successfully finds a list on the page, it will return a list of items. For each item, Extract will attempt to extract a title, summary, date, link, and image. To get these fields for each item, prefix the field name with items..
In our earlier example, we want the title and the link for each blog post on the Diffbot blog homepage, so we request these fields by entering them as "items.title, items.link".
Here's another example of extracting a list of Smithsonian museums from their website —
=EXTRACT_URL("https://www.si.edu/visit/hours", "title,items.title,items.link,items.summary", "list")
Notice that we requested title twice this time, once as the title of the page (which will be the same for each item), and once for the title of each item.
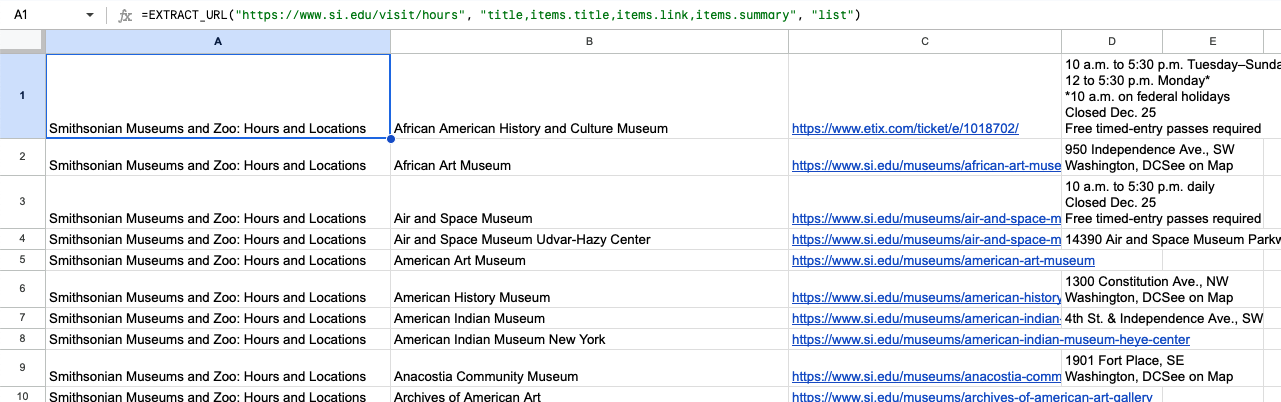
For more advanced techniques with list api, check out the list API reference.
Pull Product Data
The product API type should be generally used for e-commerce product pages to pull product images, prices, and descriptions. A complete list of data fields extracted by the product api is available here.
Here's an example of extracting the title, price, availability, and text from the product page at shop.visitthecapital.gov —
=EXTRACT_URL("https://shop.visitthecapitol.gov/u-s-capitol-jersey/", "title,offerPrice,availability,text", "product")

Pull Job Listing Data
The job API type should be used for job listing pages to pull requirements, skills, title, location, and similar job details from a job listing page. A complete list of data fields extracted by the job api is available here.
Here's an example of extracting the title, employer, location, and text from a job listing page on remote.com —
=EXTRACT_URL("https://remote.com/jobs/grafana-labs-c17v751x/principal-data-scientist-remote-canada-j157fbg7", "title,employer.name,remote,locations.country.name,locations.city.name,text", "job")

Note that this job listing might not exist anymore, but the method is functionally the same.
Pull Event Data
The event API type should be used for pages outlining the details of an event. It'll pull data like location, start/end dates, and more. A complete list of data fields extracted by the event api is available here
Here's an example of extracting the title, start date, location, and description of an event we put on with some friends in San Francisco —
=EXTRACT_URL("https://lu.ma/ozt7jtq5?tk=AQDsrM", "title,startDate,location.address,description", "event")

How to pull website data to Microsoft Excel
While we do have a Microsoft Excel add-in, it currently does not support the same EXTRACT_URL function as Google Sheets. Here are some alternative options:
- Extract the data in Diffbot Dashboard (you get access to this app when you sign up for the free plan)
- Pull the data with the Diffbot for Sheets add-on in Google Sheets and export to Excel
Updated 5 months ago